| Type: | Package |
| Title: | Fundamentos De Estadistica Descriptiva e Inferencial |
| Version: | 0.2.3 |
| Author: | Vicente Coll-Serrano [aut, cre], Rosario Martínez Verdú [aut], Cristina Pardo García [ctb] |
| Description: | Este paquete pretende apoyar el proceso enseñanza-aprendizaje de estadística descriptiva e inferencial. Las funciones contenidas en el paquete 'estadistica' cubren los conceptos básicos estudiados en un curso introductorio. Muchos conceptos son ilustrados con gráficos dinámicos o web apps para facilitar su comprensión. This package aims to help the teaching-learning process of descriptive and inferential statistics. The functions contained in the package 'estadistica' cover the basic concepts studied in a statistics introductory course. Many concepts are illustrated with dynamic graphs or web apps to make the understanding easier. See: Esteban et al. (2005, ISBN: 9788497323741), Newbold et al.(2019, ISBN:9781292315034 ), Murgui et al. (2002, ISBN:9788484424673) . |
| License: | GPL-2 | GPL-3 [expanded from: GPL] |
| Encoding: | UTF-8 |
| LazyData: | true |
| RoxygenNote: | 7.2.0 |
| URL: | https://www.uv.es/estadistic/ |
| Depends: | R (≥ 3.5.0) |
| Imports: | dplyr, tidyr, plotly, ggplot2, rio, data.table, grid, shiny, shinydashboard, knitr, gridExtra, forecast |
| NeedsCompilation: | no |
| Packaged: | 2023-05-15 17:00:34 UTC; vicen |
| Maintainer: | Vicente Coll-Serrano <estadistic@uv.es> |
| Repository: | CRAN |
| Date/Publication: | 2023-05-15 17:20:02 UTC |
Coeficiente de variación.
Description
Calcula el coeficiente de variación de Pearson.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
coeficiente.variacion(x,
variable = NULL,
pesos = NULL,
tipo = c("muestral","cuasi"))
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de x. Si x se refiere una sola variable, el argumento variable es NULL. En caso contrario, es necesario indicar el nombre o posición (número de columna) de la variable. |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
tipo |
Es un carácter. Por defecto calcula la desviación típica muestral ( |
Details
El coeficiente de variación (muestral) se obtiene a partir de la siguiente expresión:
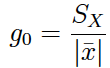
donde S es la desviación típica muestral. También puede calcularse utilizando la cuasi-desviación típica (Sc).
Value
Esta función devuelve el valor del coeficiente de variación en un objeto de la clase vector. Por defecto, el coeficiente de variación se calcula utilizando la desviación típica muestral.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N), se obtiene el coeficiente de variación poblacional:
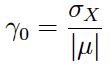
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Examples
variacion1 <- coeficiente.variacion(startup[1])
variacion2 <- coeficiente.variacion(startup)
Contraste de hipótesis de correlación
Description
Realiza el contraste de hipótesis sobre el coeficiente de correlación.
Usage
contraste.correlacion(x,
variable = NULL,
introducir = FALSE,
hipotesis_nula = 0,
tipo_contraste = "bilateral",
alfa = 0.05)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
hipotesis_nula |
Es un valor numérico. Por defecto el valor está fijado a cero (incorrelación). |
tipo_contraste |
Es un carácter. Indica el tipo de contraste a realizar. Por defecto, |
alfa |
Es un valor numérico entre 0 y 1. Indica el nivel de significación. Por defecto, |
Details
El estadístico del contraste es:
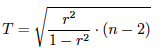
que se distribuye como una t con n-2 grados de libertad.
Value
Esta función devuelve un objeto de la clase data.frame en el que se incluye la hipótesis nula contrastada, el valor del estadístico de prueba y el p-valor.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Contraste de hipótesis sobre la diferencia de medias.
Description
Realiza el contraste de hipótesis sobre la diferencia de medias poblacionales.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
contraste.diferencia.medias(x,
variable = NULL,
introducir = FALSE,
var_pob = c("conocida","desconocida"),
iguales = FALSE,
hipotesis_nula = 0,
tipo_contraste = c("bilateral","cola derecha","cola izquierda"),
alfa = 0.05,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
var_pob |
Es un carácter. Indica si la varianza poblacional es conocida (por defecto, |
iguales |
Si las varianzas poblacionales se consideran distintas (por defecto |
hipotesis_nula |
Es un valor numérico. |
tipo_contraste |
Es un carácter. Indica el tipo de contraste a realizar. Por defecto, |
alfa |
Es un valor numérico entre 0 y 1. Indica el nivel de significación. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Value
La función devuelve un objeto de la clase list. La lista contendrá información sobre: la hipótesis nula contrastada, el estadístico de prueba, el p-valor y el intervalo de confianza para la diferencia de medias muestrales supuesta cierta la hipótesis nula. Si grafico=TRUE se incluirá una representación gráfica de la región de aceptación-rechazo.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Contraste de hipótesis sobre la diferencia de dos proporciones.
Description
Realiza el contraste de hipótesis sobre la diferencia de dos proporciones.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
contraste.diferencia.proporciones(x,
variable = NULL,
introducir = FALSE,
hipotesis_nula = 0,
tipo_contraste = c("bilateral","cola derecha","cola izquierda"),
alfa = 0.05,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
hipotesis_nula |
Es un valor numérico. Por defecto el valor está fijado en cero. |
tipo_contraste |
Es un carácter. Indica el tipo de contraste a realizar. Por defecto, |
alfa |
Es un valor numérico entre 0 y 1. Indica el nivel de significación. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
El estadístico Z del contraste, que se distribuye N(0,1), es:
(1) Si se consideran las proporciones muestrales:
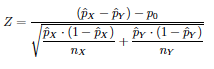
(2) si se estima p como media ponderada de las proporciones muestrales, la ponderación es:
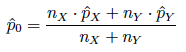
y el estadístico resulta:
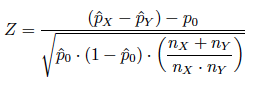
Value
La función devuelve un objeto de la clase list. La lista contendrá información sobre: la hipótesis nula contrastada, el estadístico de prueba, el p-valor el intervalo de confianza para la diferencia de proporciones muestrales supuesta cierta la hipótesis nula. Si grafico=TRUE se incluirá una representación gráfica de la región de aceptación-rechazo.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Contraste de hipótesis sobre la media.
Description
Realiza el contraste de hipótesis sobre la media poblacional.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
contraste.media(x,
variable = NULL,
introducir = FALSE,
var_pob = c("conocida","desconocida"),
hipotesis_nula = NULL,
tipo_contraste = c("bilateral","cola derecha","cola izquierda"),
alfa = 0.05,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
var_pob |
Es un carácter. Indica si la varianza poblacional es conocida (por defecto, |
hipotesis_nula |
Es un valor numérico. |
tipo_contraste |
Es un carácter. Indica el tipo de contraste a realizar. Por defecto, |
alfa |
Es un valor numérico entre 0 y 1. Indica el nivel de significación. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
(1) Si la varianza poblacional es conocida, el estadístico Z es:
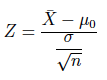
y se distribuye como una N(0,1)
Si la varianza poblacional es desconocida pero la muesta es grande, puede utilizarse la varianza (o cuasi-varianza) muestral.
(2) Si la varianza poblacional es desconocida, el estadístico T es:
(2.1) usando la varianza muestral
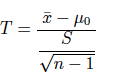
(2.2) usando la cuasi-varianza muestral
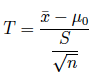
Nota: en ambos casos el estadístico T se distrubuye como un t con n-1 grados de libertad.
Value
La función devuelve un objeto de la clase list. La lista contendrá información sobre: la hipótesis nula contrastada, el estadístico de prueba, el p-valor y el intervalo de confianza para la media muestral supuesta cierta la hipótesis nula. Si grafico=TRUE se incluirá una representación gráfica de la región de aceptación-rechazo con los valores críticos y otra gráfica con el intervalo para la media muestral (supesta cierta H0).
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Contraste de hipótesis sobre la proporción.
Description
Realiza el contraste de hipótesis sobre la proporción poblacional.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
contraste.proporcion(x,
variable = NULL,
introducir = FALSE,
hipotesis_nula = NULL,
tipo_contraste = c("bilateral","cola derecha","cola izquierda"),
alfa = 0.05,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
hipotesis_nula |
Es un valor numérico. |
tipo_contraste |
Es un carácter. Indica el tipo de contraste a realizar. Por defecto, |
alfa |
Es un valor numérico entre 0 y 1. Indica el nivel de significación. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
En este caso el estadístico Z del contraste es:
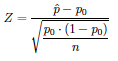
Value
La función devuelve un objeto de la clase list. La lista contendrá información sobre: la hipótesis nula contrastada, el estadístico de prueba, el p-valor y el intervalo de confianza para la proporción muestral supuesta cierta la hipótesis nula. Si grafico=TRUE se incluirá una representación gráfica de la región de aceptación-rechazo con los valores críticos.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Contraste de hipótesis sobre la razón de varianzas.
Description
Realiza el contraste de hipótesis sobre la razón de dos varianzas poblacionales.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
contraste.razon.varianzas(x,
variable = NULL,
introducir = FALSE,
hipotesis_nula = 1,
tipo_contraste = c("bilateral","cola derecha","cola izquierda"),
alfa = 0.05,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
hipotesis_nula |
Es un valor numérico. Por defecto el valor está fijado a 1, es decir, igualdad de varianzas. |
tipo_contraste |
Es un carácter. Indica el tipo de contraste a realizar. Por defecto, |
alfa |
Es un valor numérico entre 0 y 1. Indica el nivel de significación. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
La hipótesis nula que se considera en el contraste bilateral es:
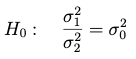
El estadístico F es:
(1) Si trabajamos con la varianza muestral:
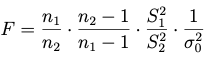
(2) si trabajamos con la cuasi-varianza muestral:
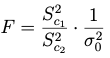
Tanto en (1) como en (2) el estadístico F se distribuye como una F con (n1-1) grados de libertad en el numerador y (n2-1) grados de libertad en el denominador.
Value
La función devuelve un objeto de la clase list. La lista contendrá información sobre: la hipótesis nula contrastada, el estadístico de prueba, el p-valor y el intervalo de confianza para la media muestral supuesta cierta la hipótesis nula. Si grafico=TRUE se incluirá una representación gráfica de la región de aceptación-rechazo con los valores críticos.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Contraste de hipótesis sobre la varianza.
Description
Realiza el contraste de hipótesis sobre la varianza poblacional.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
contraste.varianza(x,
variable = NULL,
introducir = FALSE,
media_poblacion = c("desconocida","conocida"),
hipotesis_nula = NULL,
tipo_contraste = c("bilateral","cola derecha","cola izquierda"),
alfa = 0.05,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
media_poblacion |
Es un carácter. Indica si la media de la población es desconocida (por defecto, |
hipotesis_nula |
Es un valor numérico. |
tipo_contraste |
Es un carácter. Indica el tipo de contraste a realizar. Por defecto, |
alfa |
Es un valor numérico entre 0 y 1. Indica el nivel de significación. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
(1) Si la media poblacional es desconocida, el estadístico chi-dos es:
(1.1) utilizando la varianza muestral:
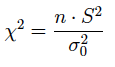
(1.2) utilizando la cuasi-varianza muestral:
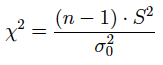
(2) Si la media poblacional es conocida.
(2.1) utilizando la varianza muestral:
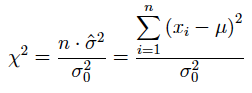
Nota: En todos los casos, el estadístico chi-dos se distrubuye con n-1 grados de libertad.
Value
La función devuelve un objeto de la clase list. La lista contendrá información sobre: la hipótesis nula contrastada, el estadístico de prueba, el p-valor y el intervalo de confianza para la media muestral supuesta cierta la hipótesis nula. Si grafico=TRUE se incluirá una representación gráfica de la región de aceptación-rechazo con los valores críticos.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Convergencia de la varianza y cuasivarianza muestral.
Description
Gráfico dinámico que ilustra la convergencia de la varianza y cuasi-varianza muestral a medida que aumenta el tamaño muestral.
Usage
convergencia.varianza()
Value
Devuelve un gráfico que es un objeto de la clase plotly y htmlwidget.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Coeficiente de correlación.
Description
Calcula el coeficiente de correlación de Pearson.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
correlacion(x, variable = NULL, pesos=NULL)
Arguments
x |
Conjunto de datos. Es un dataframe con al menos 2 variables (2 columnas). |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
Details
El coeficiente de correlación muestral se obtiene a partir de la siguiente expresión:
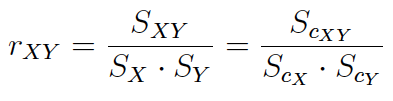
Por su construcción, el valor del coeficiente de correlación muestral es el mismo tanto si se calcula a partir de la covarianza y desviaciones típicas muestrales como si se hace a partir de la cuasi-covarianza y cuasi-desviaciones típicas muestrales.
Value
Esta función devuelve el valor del coeficiente de correlación lineal en un objeto de la clase vector.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N) se obtiene el coeficiente de correlació poblacional:
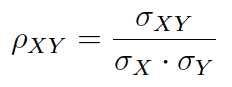
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
matriz.correlacion, covarianza,matriz.covar
Examples
correlacion1 <- correlacion(startup[,c(1,3)])
correlacion2 <- correlacion(startup,variable=c(1,3))
Covarianza.
Description
Calcula la covarianza.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
covarianza(x,
variable = NULL,
pesos = NULL,
tipo = c("muestral","cuasi"))
Arguments
x |
Conjunto de datos. Es un dataframe con al menos 2 variables (2 columnas). |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de x. Si x solo tiene 2 variables (columnas), el argumento variable es NULL. En caso contrario, es necesario indicar el nombre o posición (número de columna) de las variables a seleccionar. |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
tipo |
Es un carácter. Por defecto de calcula la covarianza muestral (tipo = "muestral"). Si tipo = "cuasi", se calcula la cuasi-covarianza muestral. |
Details
(1) La covarianza muestral se obtiene a partir de la siguiente expresión:
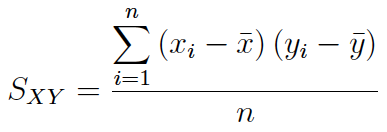
(2) Muchos manuales y prácticamente todos los softwares (SPSS, Excel, etc.) calculan la covarianza a partir de la expresión:
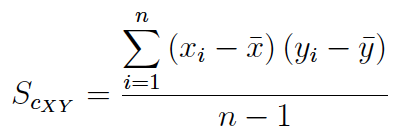
Nosotros nos referimos a esta expresión como cuasi-covarianza muestral.
Value
Esta función devuelve la covarianza en un objeto de la clase vector.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N) se obtiene la covarianza poblacional:
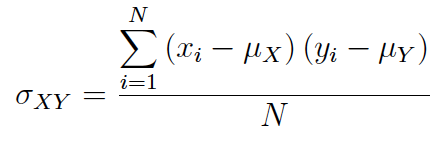
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
varianza, desviacion,matriz.covar
Cuantiles.
Description
Calcula los cuantiles.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
cuantiles(x,
variable = NULL,
pesos = NULL,
cortes = c(0.25,0.5,0.75),
exportar = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
cortes |
Vector con los puntos de corte a calcular. Por defecto se calcula el primer, segundo y tercer cuartil. |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
Details
Los cuantiles se obtienen a partir de la siguiente regla de decisión:
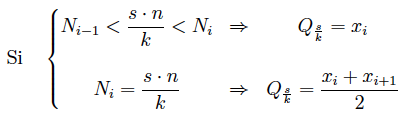
Ni son las frecuencias acumuladas y n el tamaño de la muestra (o N si es la población).
cuartiles: s=1,2,3 y k=4
deciles: s= 1,2,...,9 y k=10
percentiles: s=1,2,...,99 y k=100
Value
Si pesos = NULL, la función devuelve los cuantiles de todas las variables seleccionadas en un objeto de tipo data.frame. En caso contrario, devuelve los cuantiles de la variable para la que se ha facilitado la distribución de frecuencias.
Author(s)
Vicente Coll-Serrano (vicente.coll@uv.es). Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú (rosario.martinez@uv.es). Economía Aplicada.
Cristina Pardo-García (cristina.pardo-garcia@uv.es). Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
Examples
cuantiles1 <- cuantiles(startup[1])
cuantiles2 <- cuantiles(startup,variable=1,cortes=seq(0.1,0.9,0.1))
cuantiles3 <- cuantiles(salarios2018,variable=6,pesos=7 )
Desviación típica.
Description
Calcula la desviación típica.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.
Usage
desviacion(x,
variable = NULL,
pesos = NULL,
tipo = c("muestral","cuasi"))
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
tipo |
Es un carácter. Por defecto de calcula la desviación típica muestral ( |
Details
(1) La expresión de la de la desviación típica muestral es:
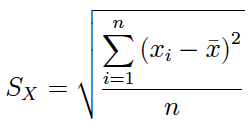
La desviación típica muestral así definida es el estimador máximo verosímil de la desviación típica de una población normal
(2) Muchos manuales y prácticamente todos los softwares (SPSS, Excel, etc.) calculan la expresión:
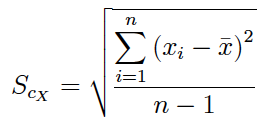
Nosotros llamamos a esta medida: cuasi-desviación típica muestral y es un estimador insesgado de la desviación típica poblacional.
Value
Esta función devuelve un objeto de la clase vector. Si tipo="muestral", devuelve la desviación típica muestral. Si tipo="cuasi", devuelve la cuasi-desviación típica muestral.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N) se obtiene la desviación típica poblacional:
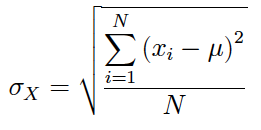
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
media, varianza, coeficiente.variacion
Examples
desviacion1 <- desviacion(startup[1])
desviaciona2 <- desviacion(startup,variable=1)
desviacion3 <- desviacion(startup,variable=1, tipo="cuasi")
Datos simulados de dos muestras tomadas en periodos de tiempo distintos. La muestra 1 es tomada en enero y la muestra 2 en junio.
Description
Datos simulados de dos muestras tomadas en periodos de tiempo distintos. La muestra 1 es tomada en enero y la muestra 2 en junio.
Usage
data("diseno1")
Format
Dataframe en formato ancho con 620 observaciones. La pregunta realizada es: ¿Sabe que Valencia es la capital mundial del diseño 2022?
- muestra1
0: No sabe, 1: Sí Sabe
- muestra2
0: No sabe, 1: Sí sabe
Author(s)
Vicente Coll-Serrano. Quantitative Methods for Measuring Culture (MC2). Applied Economics.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Source
Muestra simulada.
Datos simulados de dos muestras tomadas en periodos de tiempo distintos. La muestra 1 es tomada en enero y la muestra 2 en junio.
Description
Datos simulados de dos muestras tomadas en periodos de tiempo distintos. La muestra 1 es tomada en enero y la muestra 2 en junio.
Usage
data("diseno2")
Format
Dataframe en formato largo con 1085 observaciones. La pregunta realizada es: ¿Sabe que Valencia es la capital mundial del diseño 2022?
- muestra
Toma dos valores: Muestra1 y Muestra2
- resultado
0: No sabe, 1: Sí sabe
Author(s)
Vicente Coll-Serrano. Quantitative Methods for Measuring Culture (MC2). Applied Economics.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Source
Muestra simulada.
Distribución normal.
Description
Aplicación interactiva para comparar dos distribuciones normales.
Usage
distribucion.normal()
Value
No devuelve un valor, es una aplicación shiny.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Distribuciones de probabilidad.
Description
Aplicación interactiva donde se representa las principales distribuciones de probabilidad unidimensionales: Binomial, Poisson, Uniforme, Exponencial y Normal.
Usage
distribuciones.probabilidad()
Value
No devuelve un valor, Es una aplicación shiny.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Data: Ejemplo de dos variables (ejem_bidi)
Description
Datos simulados. Muestra de 100 observaciones
Usage
data("ejem_bidi")
Format
Dataframe con 100 observaciones de 2 variables.
- x
Toma valores de 0 a 5.
- x
Toma valores de 10 a 15
Author(s)
Vicente Coll-Serrano. Quantitative Methods for Measuring Culture (MC2). Applied Economics.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Source
Muestra simulada.
Data: Hogares
Description
Datos de 10 hogares que se utilizan en los ejemplos de (1) tabla bidimensional, (2) covarianza, (3) matriz de covarianzas, (4) correlación y (5) matriz de correlación.
Usage
data("hogares")
Format
Dataframe con 10 observaciones de 3 variables.
- Hogares
Identificación del hogar.
- ingresos
Ingresos del hogar
- viajes
Número de hogares realizado por los hogares.
Intervalo confianza para el coeficiente de correlación
Description
Calcula el intervalo de confianza para el coeficiente de correlación.
Usage
ic.correlacion(x,
variable = NULL,
introducir = FALSE,
confianza = 0.95)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
Details
(1) El intervalo para
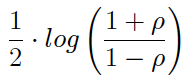
(2) es:
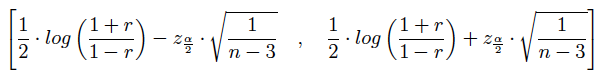
Igualando la expresión en (1) al extremo inferior de (2) y al extremo superior de (2) se obtendrá el intervalo para la correlación.
Value
Devuelve el intervalo de confianza de la correlación lineal en un objeto de tipo data.frame
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Intervalo confianza para la diferencia de medias.
Description
Calcula el intervalo de confianza de la diferencia de medias poblacionales.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
ic.diferencia.medias(x,
variable = NULL,
introducir = FALSE,
poblacion = c("normal","desconocida"),
var_pob = c("conocida","desconocida"),
iguales = FALSE,
confianza = 0.95)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
poblacion |
Es un carácter. Indica la distribución de probabilidad de la población. Por defecto |
var_pob |
Es un carácter. Indica si la varianza poblacional es conocida (por defecto, |
iguales |
Por defecto se considera que las varianzas poblacionales son distintas ( |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
Details
Se obtienen los intervalos según los siguientes casos:
Caso 1: Varianzas poblacionales conocidas
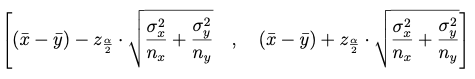
Nota: Si los tamaños muestrales nx y ny son suficientemente grandes, pueden estimarse las varianzas poblacionales por sus correspondientes varianzas (o cuasivarianzas), incluso aunque las distribuciones poblacionales no sean normales (por aplicación del TCL).
Caso 2. Varianzas poblacionales desconocidas pero iguales
(2.1) con varianza muestral:
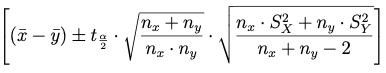
(2.2) con cuasivarianza muestral:
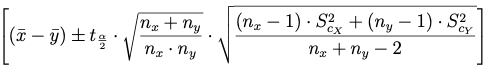
Nota: Tanto en el caso (2.1) como (2.2) la distribución t tiene (nx+ny-2) grados de libertad.
Caso 3. Varianzas poblacionales desconocidas y distintas
(3.1) con varianza muestral:
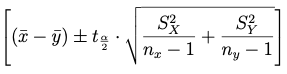
la distribución t con grados de libertad igual al entero más próximo de v.
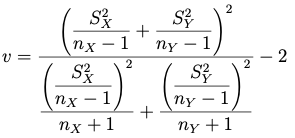
(3.2) con cuasivarianza muestral:
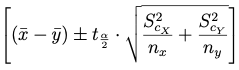
la distribución t con grados de libertad igual a v, donde v = (parte entera de v*) + 1
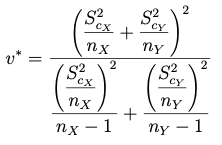
Value
Devuelve el intervalo de confianza de la diferencia de medias poblacionales en un objeto de tipo data.frame.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Intervalo confianza para la diferencia de dos proporciones.
Description
Calcula el intervalo de confianza de la diferencia de dos proporciones.

Usage
ic.diferencia.proporciones(x,
variable = NULL,
introducir = FALSE,
confianza = 0.95,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de x. Si x se refiere una sola variable, el argumento variable es NULL. En caso contrario, es necesario indicar el nombre o posición (número de columna) de la variable. |
introducir |
Valor lógico. Si introducir = FALSE (por defecto), el usuario debe indicar el conjunto de datos que desea analizar usando los argumentos x y/o variable. Si introducir = TRUE, se le solicitará al ususario que introduzca la información relevante sobre tamaño muestral, valor de la media muestral, etc. |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, confianza = 0.95 (95 por ciento) |
grafico |
Es un valor lógico. Por defecto grafico = FALSE. Si se quiere obtener una representación gráfica del intervalo de confianza obtenido, cambiar el argumento a grafico = TRUE. Nota: Esta opción no está implementada para todos los casos.#' |
Details
Se obtiene el intervalo:
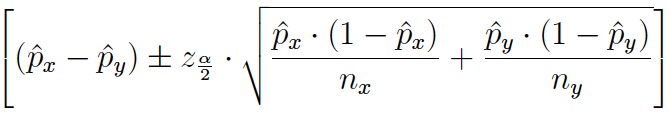
Nota: El usuario puede seguir dos estrategias: (1) Sustituir las proporciones muestrales del error típico por sus estimaciones máximo-verosímiles (proporciones muestrales) (2) Considerar el caso: p=q=0.5
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Intervalo confianza para la media.
Description
Calcula el intervalo de confianza de la media poblacional.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
ic.media(x,
variable = NULL,
introducir = FALSE,
poblacion = c("normal","desconocida"),
var_pob = c("conocida","desconocida"),
confianza = 0.95,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
poblacion |
Es un carácter. Indica la distribución de probabilidad de la población. Por defecto |
var_pob |
Es un carácter. Indica si la varianza poblacional es conocida (por defecto, |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
(1) Si población desconocida, varianza poblacial conocida y muestra pequeña:
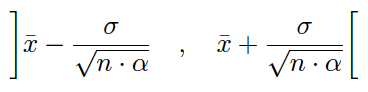
(2) Si población normal, varianza poblacional conocida (muestra pequeña y grande)
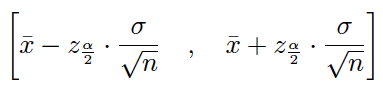
(3) Si población normal, varianza poblacional desconocida y muestra pequeña
Con la varianza muestral:
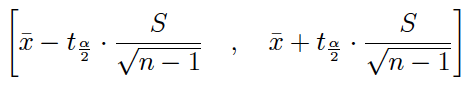
Con la cuasivarianza muestral:
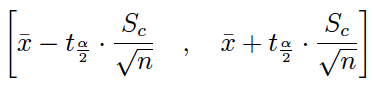
Nota: En ambos casos, el valor crítico sigue una distribución t con n-1 grados de libertad
(4) Si población normal, varianza poblacional desconocida y muestra grande: Puede utilizarse la aproximación a la normal. El intervalo se obtiene a partir de la expresión (2) estimando la varianza poblacional por la varianza (o cuasivarianza) muestral.
Value
Devuelve el intervalo de confianza de la media poblacional en un objeto de tipo data.frame. Si grafico = T devuelve una list con el intervalo de confianza y su representación gráfica.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Intervalo confianza de una proporción.
Description
Calcula el intervalo de confianza de una proporción.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
ic.proporcion(x,
variable = NULL,
introducir = FALSE,
irrestricto = FALSE,
confianza = 0.95,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
irrestricto |
Es un valor lógico. Por defecto, irrectricto = FALSE. si se considera un muestreo irrectricto (extracción sin reemplazamiento), cambiar el argumento a irrestricto = TRUE. |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
(1) Para tamaños muestrales muy grandes (n>100):
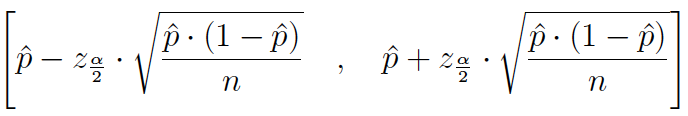
El usuario puede elegir entre tres estrategias:
(1.1) En el error típico aproximar p por su estimación muestral. (1.2) En el error típico considerar el caso: p=q=0.5 (1.3) Obtener el valor de p a partir del estadístico.
(2) Para cualquier tamaño muestral puede obtenerse el intervalo:
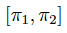
correspondiendo los valores a las raíces de:
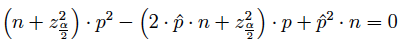
Value
Devuelve el intervalo de confianza de la proporción poblacional en un objeto de tipo data.frame. Si grafico = T devuelve una list con el intervalo de confianza y su representación gráfica.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Intervalo confianza para la razón (cociente) de varianzas.
Description
Calcula el intervalo de confianza para la razón (o cociente) de varianzas.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
ic.razon.varianzas(x,
variable = NULL,
introducir = FALSE,
media_pob = c("desconocida","conocida"),
confianza = 0.95,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
media_pob |
Es un carácter. Por defecto se supone que la media poblacional es desconocida ( |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
Esta función calcula el intervalo de confianza para el cociente entre la varianza poblacional de la muestra 1 y la de la muestra 2, es decir:
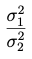
Para obtener los intervalos de confianza se opera sobre el estadístico F que se facilita en la nota y que se utiliza para obtener el intervalo del cociente de la varianza de la muestra 2 y la muestra 1.
Los intervalos se obtienen bajo el supuesto de que la media poblacional es desconocida:
(1) si se trabaja con las varianzas muestrales
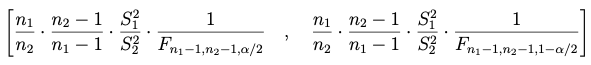
(2) si se trabaja con las cuasi-varianzas muestrales
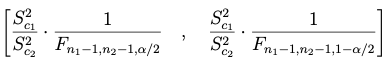
Value
Devuelve el intervalo del cociente de varianzas poblacionales en un objeto de tipo data.frame. Si grafico = T devuelve una list con el intervalo de confianza y su representación gráfica.
Note
En el caso de querer deducir el intervalo recíproco, es decir:
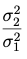
se parte del estadístico:
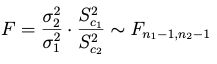
(3) si se trabaja con las varianzas muestrales
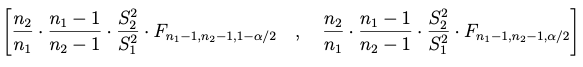
(4) si se trabaja con las cuasi-varianzas muestrales
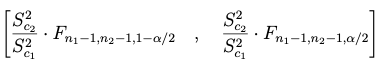
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Intervalo confianza para la varianza.
Description
Calcula el intervalo de confianza de la varianza poblacional.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
ic.varianza(x,
variable = NULL,
introducir = FALSE,
media_poblacion = c("desconocida","conocida"),
confianza = 0.95,
grafico = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
introducir |
Valor lógico. Si |
media_poblacion |
Es un carácter. Indica si la media de la población es desconocida (por defecto, |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
grafico |
Es un valor lógico. Por defecto |
Details
(1) Si la media poblacional es conocida:
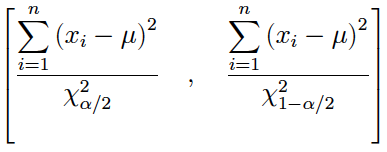
(2) Si la media poblacional es desconocida.
Con la varianza muestral:
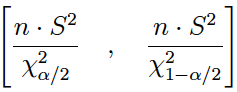
Con la cuasivarianza muestral:
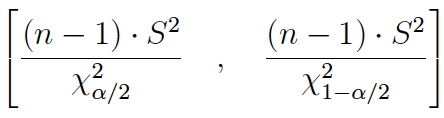
Nota: En todos los casos se obtiene el valor de la chi-dos con n grados de libertad que deja a su derecha una probabilidad de alfa y 1-alfa.
Value
Devuelve el intervalo de confianza de la varianza poblacional en un objeto de tipo data.frame. Si grafico = T devuelve una list con el intervalo de confianza y su representación gráfica.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editorial: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Leer datos.
Description
Carga un conjunto de datos.

Usage
leer.datos(introducir = FALSE, pos = 1)
Arguments
introducir |
Valor lógico. Si |
pos |
Es un valor fijo utilizado para mostrar el dataframe del usuario en el Global Environment. |
Value
Al finalizar el proceso de lectura de datos se mostrará el dataframe cargado en el environment.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. et al. (2005). Estadística descriptiva y nociones de probabilidad. Thomson.
Matriz de correlación.
Description
Obtiene la matriz de correlación (de Pearson) entre 2 o más variables cuantitativas.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.
Usage
matriz.correlacion(x, variable = NULL, exportar = FALSE)
Arguments
x |
Conjunto de datos. Es un dataframe con al menos 2 variables (2 columnas). |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
Details
Se obtiene la matriz de correlación muestral:
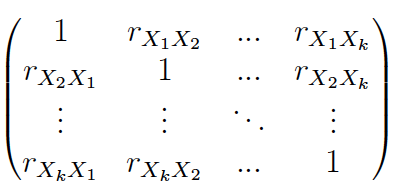
Value
La función devuelve la matriz de correlación lineal de las variables seleccionadas en un data.frame.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N) se obtiene la matriz de correlació poblacional:
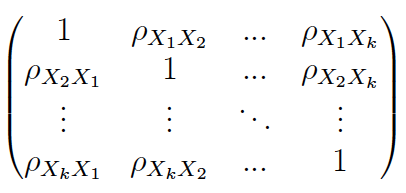
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
correlacion, covarianza,matriz.covar
Examples
matriz_cor <- matriz.correlacion(startup)
Matriz de varianzas y covarianzas.
Description
Obtiene la matriz de varianzas y covarianzas.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.
Usage
matriz.covar(x,
variable = NULL,
tipo = c("muestral","cuasi"),
exportar = FALSE)
Arguments
x |
Conjunto de datos. Es un dataframe con al menos 2 variables (2 columnas). |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
tipo |
Es un carácter. Por defecto de calcula la matriz de varianzas y covarianzas muestrales ( |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
Details
(1) Se obtiene la matriz de varianzas y covarianzas muestrales:
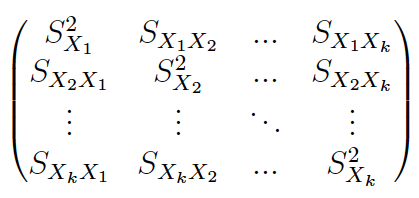
(2) Muchos manuales y prácticamente todos los softwares (SPSS, Excel, etc.) facilitan la matriz de cuasi-varianzas y cuasi-covarianzas muestrales:
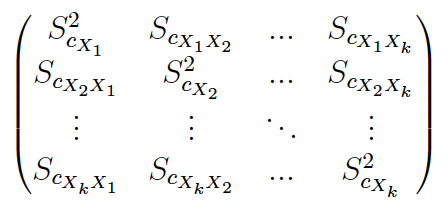
Nosotros nos referimos a esta expresión como cuasi-covarianza muestral.
Value
La función devuelve la matriz de varianzas-covarianzas (muestrales, por defecto) de las variables seleccionadas en un data.frame.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N) se obtiene la matriz de varianzas y covarianzas poblacional:
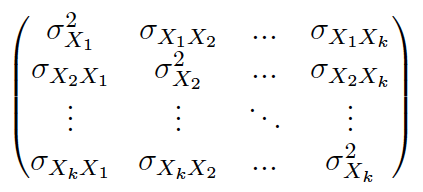
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
Examples
matriz_covarianzas1 <- matriz.covar(startup)
matriz_covarianzas2 <- matriz.covar(startup, tipo= "cuasi")
Media (aritmética).
Description
Calcula la media aritmética.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
media(x, variable = NULL, pesos = NULL)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
Details
Si se obtiene la media (muestral) a partir de los datos brutos, como generalmente hacen los softwares:
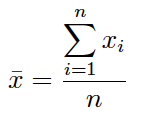
Si se desea obtener la media (muestral) a partir de una tabla estadística se utiliza la expresión:
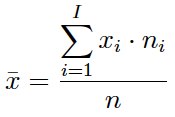
Value
Si pesos = NULL, devuelve la media (aritmética) de todas la variables seleccionadas en un vector. En caso contrario, devuelve únicamente la media de la variable para la que se ha facilitado la distribución de frecuencias.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N) se obtiene la media poblacional:
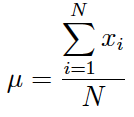
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Examples
media1 <- media(startup[1])
media2 <- media(startup,variable=1)
media3 <- media(salarios2018,variable=6,pesos=7)
Mediana.
Description
Calcula la mediana.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.
Usage
mediana(x, variable = NULL, pesos = NULL)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
Details
La mediana se obtiene a partir de la siguiente regla de decisión:
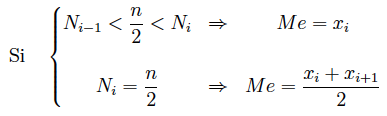
donde: Ni son las frecuencias acumuladas y n el tamaño de la muestra (o N si es la población).
Value
Si pesos = NULL, devuelve la mediana de todas la variables seleccionadas en un vector. En caso contrario, devuelve únicamente la mediana de la variable para la que se ha facilitado la distribución de frecuencias.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
Examples
mediana1 <- mediana(startup[1])
mediana2 <- mediana(startup,variable=1)
mediana3 <- mediana(salarios2018,variable=6,pesos=7)
Medidas de forma
Description
Calcula el coeficiente de asimetría y de curtosis de Fisher.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
medidas.forma(x,
variable = NULL,
pesos = NULL,
alternativa = FALSE,
exportar = FALSE)
Arguments
x |
Conjunto de datos, que puede estar formado por una o más variables. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de x. Si x se refiere una sola variable, el argumento variable es NULL. En caso contrario, es necesario indicar el nombre o posición (número de columna) de la variable. |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
alternativa |
Es un valor lógico. Si alternativa = TRUE el resultado de las medidas de forma muestra el coeficiente de asimetría y curtosis calculado según SPSS y EXCEL. Se facilita también los correspondientes errores típicos. Este argumento no funciona si pesos = NULL. |
exportar |
Para exportar los resultados a una hoja de cálculo Excel (exportar = TRUE). |
Details
El coeficiente de asimetría se obtiene a partir de la expresión:
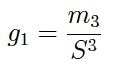
y el coeficiente de curtosis:
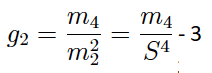
Note
(1) El coeficiente de asimetría poblacional es:
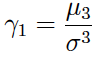
(2) El coeficiente de curtosis poblacional es:
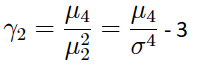
(3) Si el argumento alternativa = TRUE, se obtienen los resultados de asimetría y curtosis que generalmente ofrecen softwares como: SPSS, Stata, SAS, Excel, etc.
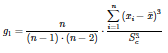
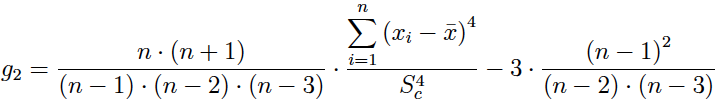
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
momento.central,varianza,desviacion
Examples
forma <- medidas.forma(startup)
forma2 <- medidas.forma(startup, alternativa= TRUE)
Moda.
Description
Calcula la moda.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.
Usage
moda(x, variable = NULL, pesos = NULL)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
Value
Si pesos = NULL, devuelve la moda de todas la variables seleccionadas en un data.frame. En caso contrario, devuelve únicamente la moda de la variable para la que se ha facilitado la distribución de frecuencias.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Momento central.
Description
Calcula los momentos centrales respecto de la media.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.
Usage
momento.central(x, orden)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
orden |
Es un valor numérico que representa el orden del momento central (orden = 1,2,3,4,...) |
Value
Devuelve el valor de momento central de orden seleccionado
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Tamaño de la muestra.
Description
Calcula el tamaño muestral para estimar la media de una población normal o la proporcion p de una población.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.


Usage
muestra(poblacion = c("normal","dicotomica"),
error_estimacion = NULL,
confianza = 0.95,
irrestricto = FALSE)
Arguments
poblacion |
Texto, si |
error_estimacion |
Es un valor que establece el error de estimación. Es la semiamplitud (mitad de la precisión) del intervalo de confianza. Esta aproximación solo es válida en distribuciones simétricas (normal o t-student). |
confianza |
Es un valor entre 0 y 1 que indica el nivel de confianza. Por defecto, |
irrestricto |
Es un valor lógico que indica si se considera un muestreo aleatorio simple (por defecto, |
Details
(1) El tamaño muestral para estimar la media poblacional se obtiene a partir de la siguiente expresión:
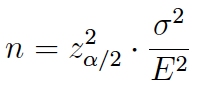
y si el muestreo es irrestricto:
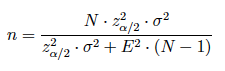
Nota: si la varianza poblacional no es conocida puede estimarse a través de la varianza (o cuasi-varianza) muestral.
(2) El tamaño muestral para estimar la proporción de una característica se obtiene a partir de la expresión:
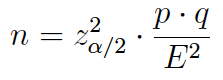
y si el muestreo es irrectricto:
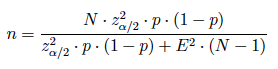
Nota: puede estimarse la proporción poblacional por la proporción muestral o, en caso de no disponer de información, suponer el caso más desfavorable: p=q=0.5
Value
Devuelve el tamaño de la muesta en un objeto de tipo data.frame.
Note
En el caso del tamaño muestral para la media: si la varianza poblacional no es conocida puede estimarse con la varianza muestral (o cuasivarianza muestral). En el caso del tamaño muestral para la proporción: si la proporción poblacional no es conocida, puede estimarse por la proporción muestral o considerar el caso más desfavorable (p=q=0.5)
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. (1997) Inferencia estadística. Editoral: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Nivel de confianza.
Description
Esta función simula una población de tamaño 100,000 de la que se extraen diversas muestras y construye los correspondientes intervalos de confianzas. El objetivo es transmitir el concepto de nivel de confianza.
Usage
nivel.confianza(min.pob = 2000,
max.pob = 45000,
muestras = 200,
n = 100,
confianza = 0.95,
grafico = TRUE,
exportar = FALSE,
replicar = FALSE)
Arguments
min.pob |
Es un valor numérico que indica el valor mínimo poblacional. Por defecto |
max.pob |
Es un valor numérico que indica el valor máximo poblacional. Por defecto |
muestras |
Es un valor numérico entre 50 y 10000 que indica el número de muestras que se extraen sin reemplazamiento de la población. Por defecto |
n |
Es un valor numérico entre 25 y 2000 que indica el tamaño de la muestra. Por defecto |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
grafico |
Si |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
replicar |
Es un valor lógico. Si |
Value
Esta función devuelve un gráfico como un objeto de la clase list. La lista contiene los valores simulados para las muestras, el porcentaje de intervalos que contienen la media poblacional y su representación gráfica.
Note
Si se seleccionan 10000 muestras de tamaño 2000, el tiempo estimado de ejecución es de 9 minutos.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Casas José M. () Inferencia estadística. Editoral: Centro de estudios Ramón Areces, S.A. ISBN: 848004263-X
Esteban García, J. et al. (2008). Curso básico de inferencia estadística. ReproExprés, SL. ISBN: 8493036595.
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
See Also
Regresión lineal simple.
Description
Calcula la regresión lineal simple.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.


Usage
regresion.simple(x,
var_depen = NULL,
var_indepen = NULL,
introducir = FALSE,
inferencia = FALSE,
confianza = 0.95,
grafico = FALSE,
exportar = FALSE)
Arguments
x |
Conjunto de datos. Es un dataframe con al menos 2 variables (2 columnas). |
var_depen |
Es un vector (numérico o carácter) que indica la variable dependiente. |
var_indepen |
Es un vector (numérico o carácter) que indica la variable independiente. |
introducir |
Valor lógico. Si |
inferencia |
Si |
confianza |
Es un valor numérico entre 0 y 1. Indica el nivel de confianza. Por defecto, |
grafico |
Si |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
Details
Se obtiene la recta de regresión minimocuadrática de Y (variable dependiente) en función de X (variable independiente). La recta de regresión puede expresarse como:
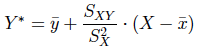
o alternativamente:
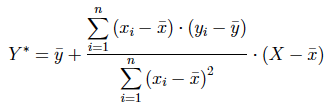
En las representaciones gráficas las observaciones anómals se detectan a partir del punto leverage:
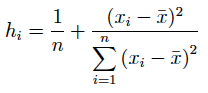
de forma que una observación tendrá efecto de apalancamiento si:
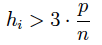
donde p=2 (en el caso de la regresión simple). En general, p es igual al número de variables independientes más la constante.
Por otra parte, las observaciones atípicas se identifican a partir de los errores estandarizados (se). Estos errores se obtienen a partir de:
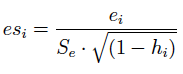
Una observación será atípica si:
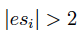
@seealso matriz.covar, matriz.correlacion
Value
Si inferencia = FALSE, la función devuelve los principales resultados de la regresión lineal simple que se estudian en estadística descriptiva en un objeto de la clase data.frame.
Si inferencia = TRUE, la función devuelve los resultados de inferenciales de la regresión. Estos contenidos son estudiados en cursos de inferencia estadística y en temas introductorios de econometría.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Examples
## Not run:
ejemplo_regresion <- regresion.simple(turistas,
var_depen=2,var_indepen=3,grafico=TRUE)
## End(Not run)
Resumen descriptivos.
Description
Calcula un resumen de los principales estadísticos descriptivos.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
resumen.descriptivos(x,
variable = NULL,
pesos = NULL,
exportar = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
Value
Esta función devuelve los principales estadísticos descriptivos muestrales en un objeto de tipo data.frame. Los descriptivos que se obtienen son: media, mínimo, cuartil 1, mediana, cuartil 3, máximo, varianza muestral, desviación típica muestral, coeficiente de variación, recorrido inter-cuartílico, asimetría, curtosis y moda.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Examples
descriptivos <- resumen.descriptivos(startup)
Data: Encuesta cuatrienal de estructura salarial (2018)
Description
Datos del Instituto Nacional de Estadística. Hay un total de 216,726 observaciones de 10 variables seleccionadas. Los datos han sido tratados siguiendo las instrucciones que el INE adjunta con los microdatos.
Usage
data("salarios2018")
Format
Dataframe con 216,726 observaciones de 7 variables.
- SEXO
Sexo (1=hombre, 6=mujer)
- ESTUDIOS
Nivel de estudios. 1=Menos que primaria,2=Primaria,3=Primera etapa secundaria,4=Segunda etapa secundaria,5=FP superior o similar,6=Diplomado o similar,7=Licenciados o similares y doctores
- TIPO.JORNADA
Tipo de jornada laboral. 1=Tiempo completo,2=Tiempo parcial
- TIPO.CONTRATO
Tipo de contrato laboral. 1=Indefinido,2=Duración determinada
- SALARIO.BRUTO.ANUAL
Salario bruto anual
- SALARIO.ORDINARIO.ANUAL
Salario ordinario anual
- FACTOR.ELEVACION
Factor de elevación
Author(s)
Vicente Coll-Serrano. Quantitative Methods for Measuring Culture (MC2). Applied Economics.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Source
Instituto Nacional de Estadística http://www.ine.es/
Series temporales.
Description
Esta función utiliza el método de las medias móviles (centradas) para extraer la tendencia de una serie temporal. A partir de las medias móviles, también se obtienen los índices de variación estacional (IVE).
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
series.temporales(x,
variable = NULL,
inicio_anual = 1,
periodo_inicio = 1,
frecuencia = 4,
orden = frecuencia,
prediccion_tendencia = FALSE,
grafico = FALSE,
exportar = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
inicio_anual |
Año de inicio de la serie. Por defecto |
periodo_inicio |
Periodo de inicio de la serie. Por defecto |
frecuencia |
Periodificación de la serie. Por defecto |
orden |
Orden (o puntos) de cálculo de la media móvil. Por defecto |
prediccion_tendencia |
vector de periodo temporal ( |
grafico |
Es un valor lógico. Por defecto |
exportar |
Para exportar los principales resultados a una hoja de cálculo Excel ( |
Value
Esta función devuelve un objeto de la clase list.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
Examples
ejemplo_serie <- series.temporales(turistas2,
variable=2,
inicio_anual=2000,
periodo_inicio = 1)
Data: Datos de empresas emergentes (startups)
Description
Datos simulados. Muestra de 21 empresas emergentes
Usage
data("startup")
Format
Dataframe con 21 observaciones de 4 variables.
- gasto.desarrollo
Gastos de investigación y desarrollo, en euros.
- gasto.marketing
Gastos de marketing, en euros.
- gasto.gestion
Gastos de administración, en euros.
- beneficio
Beneficios, en euros.
Author(s)
Vicente Coll-Serrano. Quantitative Methods for Measuring Culture (MC2). Applied Economics.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Source
Muestra simulada.
Tabla doble entrada.
Description
Calcula la tabla de frecuencias bidimensionales.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
tabla.bidimensional(x,
var_filas = NULL,
var_columnas = NULL,
distribucion = c("cruzada","condicionada"),
frecuencias = c("absolutas","relativas"),
exportar = FALSE)
Arguments
x |
Conjunto de datos. Tiene que ser un dataframe (al menos dos variables, es decir, dos columnas). |
var_filas |
Variable fila.Por defecto su valor es NUll y el usuario debe escribir el nombre o posición de la variable cuyos valores quiere representar por filas. |
var_columnas |
Variable columna. Por defecto su valor es NUll y el usuario debe escribir el nombre o posición de la variable cuyos valores quiere representar por columnas |
distribucion |
Es un carácter. Por defecto se obtien la tabla cruzada ( |
frecuencias |
Es un carácter. Por defecto se obtienen las frecuencias absolutas ordinarias ( |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
Value
Devuelve la tabla cruzada de las dos variables seleccionadas en un data.frame
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Tabla de frecuencias.
Description
Esta función presenta la distribución de frecuencias de una variable cuantitativa o cualitativa.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.

Usage
tabla.frecuencias(x,
eliminar.na = TRUE,
grafico = FALSE,
exportar = FALSE)
Arguments
x |
Conjunto de datos. Puede ser un vector (numérico o factor) o un dataframe. Si el dataframe tiene más de una variable, solicitará al usuario que idenfique el nombre de la variable para la que se quiere calcular la tabla de frecuencias. |
eliminar.na |
Valor lógico. Por defecto |
grafico |
Si |
exportar |
Para exportar los resultados a una hoja de cálculo Excel ( |
Value
Devuelve la tabla de frecuencias como una tibble. Si grafico = TRUE, se devuelve en una lista la tabla de frecuencias y su representación gráfica.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
Data: Turistas por paises (WTO)
Description
Datos de World Tourism Organization.
Usage
data("turistas")
Format
Dataframe con 130 observaciones de 3 variables.
- País
País de destino.
- Llegadas.turistas
Número de llegada de turistas en 2017, en miles.
- Gasto.viajes
Gasto en viajes en 2017, en millones de USD.
Source
World Tourism Organization (2019).
Data: Turistas internacionales Comunidad Valenciana
Description
Data: Turistas internacionales Comunidad Valenciana
Usage
data("turistas")
Format
Dataframe con 80 observaciones de 2 variables.
- perido
Periodo temporal.
- Turistas.internacionales
Número de turistas con destino principal la Comunidad Valenciana
Source
Movimientos turísticos en fronteras. Frontur. Instituto de Estudios Turísticos (hasta septiembre de 2015) e INE (a partir de octubre de 2015)
Unir vectores.
Description
Une dos o más vectores numéricos de igual o distinta longitud.
Usage
unir.vectores(...)
Arguments
... |
Introducir los nombres de los objetos, vectores, que se quiere unir. Si los vectores tienen distinta longitud se rellenarán los espacios con NAs. |
Value
La función devuelve un dataframe.
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
Varianza.
Description
Calcula la varianza.
Lee el código QR para video-tutorial sobre el uso de la función con un ejemplo.
Usage
varianza(x,
variable = NULL,
pesos = NULL,
tipo = c("muestral","cuasi"))
Arguments
x |
Conjunto de datos. Puede ser un vector o un dataframe. |
variable |
Es un vector (numérico o carácter) que indica las variables a seleccionar de |
pesos |
Si los datos de la variable están resumidos en una distribución de frecuencias, debe indicarse la columna que representa los valores de la variable y la columna con las frecuencias o pesos. |
tipo |
Es un carácter. Por defecto de calcula la varianza muestral ( |
Details
(1) La expresión de la varianza muestral es:
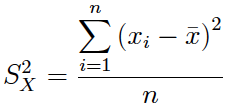
La varianza muestral así definida es el estimador máximo verosímil de la varianza de una población normal
(2) Muchos manuales y prácticamente todos los softwares (SPSS, Excel, etc.) calculan la expresión:
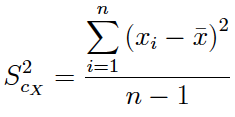
Nosotros llamamos a esta medida: cuasi-varianza muestral y es un estimador insesgado de la varianza poblacional.
Value
Esta función devuelve un objeto de la clase vector. Si tipo="muestral", devuelve la varianza muestral. Si tipo="cuasi", devuelve la cuasi-varianza muestral.
Note
Si en lugar del tamaño muestral (n) se utiliza el tamaño de la población (N) se obtiene la varianza poblacional:
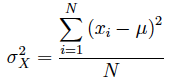
Author(s)
Vicente Coll-Serrano. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Rosario Martínez Verdú. Economía Aplicada.
Cristina Pardo-García. Métodos Cuantitativos para la Medición de la Cultura (MC2). Economía Aplicada.
Facultad de Economía. Universidad de Valencia (España)
References
Esteban García, J. y otros. (2005). Estadística descriptiva y nociones de probabilidad. Paraninfo. ISBN: 9788497323741
Newbold, P, Carlson, W. y Thorne, B. (2019). Statistics for Business and Economics, Global Edition. Pearson. ISBN: 9781292315034
Murgui, J.S. y otros. (2002). Ejercicios de estadística Economía y Ciencias sociales. tirant lo blanch. ISBN: 9788484424673
See Also
media, desviacion, coeficiente.variacion
Examples
varianza1 <- varianza(startup[1])
varianza2 <- varianza(startup,variable=1)
varianza3 <- varianza(startup,variable=1, tipo="cuasi")
Data: Viajes vendidos
Description
Datos de 5 observaciones que se utilizan en los ejemplos de (1) media, mediana y moda, (2) cuantiles, (3) varianza, desviación típica y coeficiente de variación, (4) medidas de forma y momento central y (5) resumen de descriptivos
Usage
data("viajes_vendidos")
Format
Dataframe con 5 observaciones de 3 variables.
- Número.de.viajes.vendidos
Número de viajes perdidos.
- Empleados
Número de empleados
- Ni
Frecuencia absoluta acumulada del número de empleados